Uno de los mayores cambios en el análisis de datos en la última década es el paso de la construcción de cubos de datos OLAP a la ejecución de cargas de trabajo OLAP directamente en las bases de datos columnares.
El declive del cubo OLAP es un gran cambio, especialmente si ha desarrollado su carrera en análisis de datos en las últimas tres décadas. Puede parecerle extraño que los cubos OLAP, que fueron tan dominantes en los últimos 50 años de inteligencia empresarial, desaparezcan. Y podría ser justamente escéptico de este cambio a bases de datos en columnas. ¿Cuáles son las compensaciones? Cuales son los costos? ¿Es este movimiento realmente tan bueno como todos los nuevos vendedores dicen que es? Y, por supuesto, hay esa voz detrás de tu cabeza, preguntando: ¿es solo otra moda que desaparecerá, como el movimiento NoSQL antes? ¿Durará incluso?
Este ensayo busca ser un recurso exhaustivo sobre la historia y el desarrollo del cubo OLAP, y el cambio actual que lo aleja. Comenzaremos con definiciones de la terminología (OLAP vs OLTP), cubriremos la aparición del cubo OLAP y luego exploraremos la aparición de almacenes de datos en columnas como un enfoque alternativo para las cargas de trabajo OLAP.
Esta pieza está escrita pensando en el novato. Si eres una persona con más experiencia en análisis de datos, no dudes en saltarte las primeras secciones para llegar a las partes interesantes al final de este artículo. Vamos a sumergirnos.
¿Qué diablos es OLAP?
El procesamiento analítico en línea (u OLAP) es un término elegante que se utiliza para describir una cierta clase de aplicaciones de bases de datos. El término fue inventado por la leyenda de la base de datos Edgar F. Codd, en un paper de 1993 titulado Providing OLAP to User-Analysts: An IT Mandate (Proporcionando OLAP a analistas de usuarios: un mandato de TI).
La creación del término de Codd no estuvo exenta de controversia. Un año antes de publicar el documento, Arbor Software había lanzado un producto de software llamado Essbase y, ¡sorpresa, sorpresa! - El paper de Codd definió las propiedades que se ajustaban perfectamente al conjunto de características de Essbase.
La revista Computerworld pronto descubrió que Arbor había pagado a Codd para 'inventar' OLAP como una nueva categoría de aplicaciones de bases de datos, con el fin de vender mejor su producto. Codd fue llamado por su conflicto de intereses y se vio obligado a retractarse de su documento ... pero parece que sin muchas consecuencias: hoy, Codd todavía es considerado como 'el padre de la base de datos relacional', y OLAP se ha mantenido como una categoría desde entonces.
'Entonces, ¿qué es OLAP?' usted se preguntará. La forma más fácil de explicar esto es describir los dos tipos de uso de aplicaciones empresariales. Digamos que tienes un concesionario de autos. Hay dos tipos de operaciones respaldadas por bases de datos que debe realizar:
- Debe usar una base de datos como parte de algún proceso comercial. Por ejemplo, su vendedor vende el último Honda Civic a un cliente, y usted necesita registrar esta transacción en una aplicación comercial. Lo hace por razones operativas: necesita una forma de realizar un seguimiento del acuerdo, necesita una forma de contactar al cliente cuando el préstamo o el seguro del automóvil finalmente se aprueba, y lo necesita para calcular los bonos de ventas para su vendedor al final del mes.
- Utiliza una base de datos como parte del análisis. Periódicamente, deberá recopilar números para comprender cómo va su negocio en general. En su artículo de 1993, Codd llamó a esta actividad "apoyo para la toma de decisiones". Estas consultas son cosas como '¿cuántos Honda Civics se vendieron en Londres en los últimos 3 meses?' y '¿quiénes son los vendedores más productivos?' y '¿los sedanes o SUV se venden mejor en general?' Estas son preguntas que usted hace al final de un mes o un trimestre para guiar su planificación comercial para el futuro cercano.
La primera categoría de uso de la base de datos se conoce como 'Procesamiento de transacciones en línea' u 'OLTP'. La segunda categoría de uso de la base de datos se conoce como 'Procesamiento analítico en línea' u 'OLAP'.
O, como me gusta pensar en ello:
- OLTP: uso de una base de datos para administrar su negocio
- OLAP: usando una base de datos para entender su negocio
¿Por qué tratamos estas dos categorías de manera diferente? Como resultado, los dos tipos de uso tienen patrones de acceso a datos muy diferentes.
Con OLTP, ejecuta cosas como 'registrar una transacción de ventas: un Honda Civic de Jane Doe en la sucursal de Londres el 1 de enero de 2020'.
Con OLAP, sus consultas pueden volverse increíblemente complejas: "deme las ventas totales de Honda Civics verde en el Reino Unido durante los últimos 6 meses" o "dígame cuántos autos vendió Jane Doe el mes pasado" y "dígame qué tan bien ¿Los autos Honda hacen este trimestre en comparación con el trimestre anterior? Las consultas en la última categoría agregan datos a través de muchos más elementos en comparación con las consultas para la primera.
En nuestro ejemplo de un concesionario de automóviles, es posible que pueda obtener una forma de ejecutar los tipos de consulta OLTP y OLAP en una base de datos relacional normal. Pero si maneja grandes cantidades de datos, por ejemplo, si está consultando una base de datos global de ventas de automóviles durante la última década, se vuelve importante estructurar sus datos para el análisis por separado de la aplicación comercial. No hacerlo provocaría graves problemas de rendimiento.
Los desafíos de rendimiento de OLAP
Para darle una intuición sobre el tipo de dificultades de rendimiento de las que estamos hablando, piense en las consultas que debe hacer cuando analiza las ventas de automóviles en un concesionario de automóviles.
- Dame las ventas totales de Honda Civics verde en el Reino Unido durante los últimos 6 meses
- Dime cuántos autos vendió Jane Doe el mes pasado
- ¿Cuántos automóviles Honda vendimos este trimestre en comparación con el trimestre anterior?
Estas consultas se pueden reducir a varias dimensiones , propiedades por las que queremos filtrar. Por ejemplo, es posible que desee recuperar datos agregados por:
- fecha (incluyendo mes, año y día)
- Modelo de auto
- fabricante de automóviles
- vendedor
- color del auto
- cantidad de transacción
Si almacenara estos datos en una base de datos relacional típica, se vería obligado a escribir algo como esto para recuperar una tabla de resumen tridimensional:

Un roll-up tridimensional requiere 3 de tales uniones. Esto es generalizable: resulta que agregar N dimensiones requiere N de tales uniones.
Puede pensar que esto ya es bastante malo, pero este no es el peor ejemplo que existe. Digamos que desea hacer una tabulación cruzada, o lo que los usuarios avanzados de Excel llaman una 'tabla dinámica'. Un ejemplo de una tabulación cruzada se ve así:
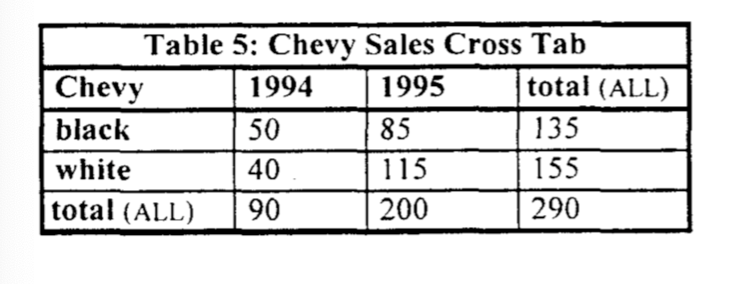
Las tabulaciones cruzadas requieren una combinación aún más complicada de uniones y GROUP BYcláusulas. Una tabulación cruzada de seis dimensiones, por ejemplo, requiere una unión de 64 vías de 64 GROUP BY operadores diferentes para construir la representación subyacente. En la mayoría de las bases de datos relacionales, esto da como resultado 64 escaneos de los datos, 64 tipos o hashes, y una espera terriblemente larga.
Los profesionales de inteligencia empresarial se dieron cuenta muy pronto de que era una mala idea usar bases de datos SQL para grandes cargas de trabajo OLAP. Esto empeoró por el hecho de que las computadoras no eran particularmente potentes: en 1995, por ejemplo, 1GB de RAM costaba $ 32,300, ¡un precio loco por la cantidad de memoria que damos por sentado hoy! Esto significaba que la gran mayoría de los usuarios empresariales tenían que usar memorias relativamente pequeñas para ejecutar cargas de trabajo de BI. Los primeros profesionales de BI se decidieron por un enfoque general: tomar solo los datos que necesita de su base de datos relacional y luego insertarlos en una estructura de datos eficiente en la memoria para su manipulación.
El surgimiento del cubo OLAP
El cubo OLAP surgió de una idea simple en la programación: tomar datos y ponerlos en lo que se conoce como 'matriz de 2 dimensiones', es decir, una lista de listas. La progresión natural aquí es que cuantas más dimensiones desee analizar, más matrices anidadas usaría: una matriz tridimensional es una lista de listas, una matriz 4 dimensiones es una lista de listas de listas, y así. Debido a que existen matrices anidadas en todos los principales lenguajes de programación, la idea de cargar datos en dicha estructura de datos fue obvia para los diseñadores de los primeros sistemas de BI.
Pero, ¿qué sucede si desea ejecutar análisis en conjuntos de datos que son mucho más grandes que la memoria disponible de su computadora? Los primeros sistemas de BI decidieron hacer lo siguiente lógico: agregaron y luego almacenaron en caché subconjuntos de datos dentro de la matriz anidada, y ocasionalmente persistieron partes de la matriz anidada en el disco. Hoy en día, los 'cubos OLAP' se refieren específicamente a contextos en los que estas estructuras de datos superan con creces el tamaño de la memoria principal de la computadora host; los ejemplos incluyen conjuntos de datos de varios terabytes y series temporales de datos de imágenes.
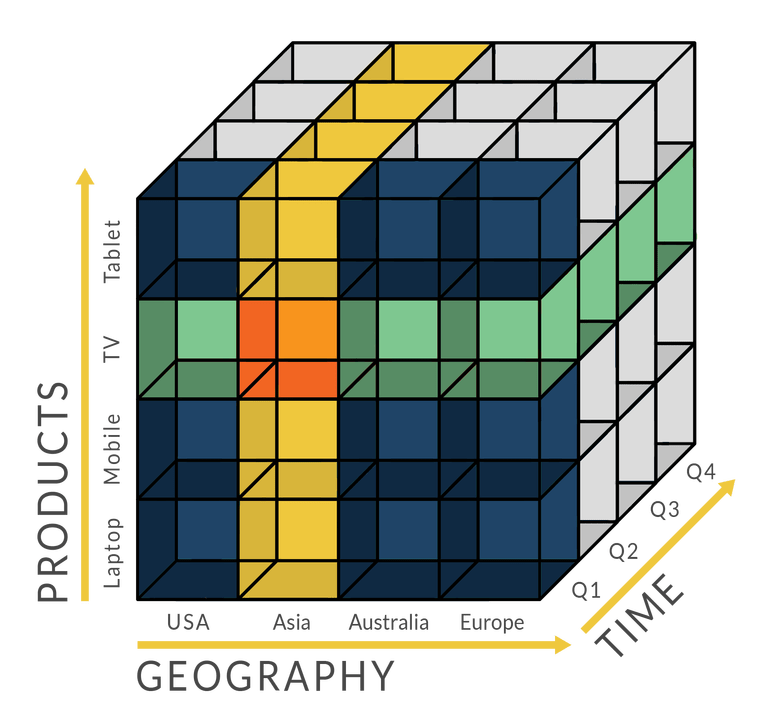
El impacto del cubo OLAP fue profundo, y cambió la práctica de la inteligencia empresarial hasta el día de hoy. Para empezar, casi todos los análisis comenzaron a hacerse dentro de tales cubos. Esto a su vez significaba que a menudo debían crearse nuevos cubos cada vez que se requería un nuevo informe o un nuevo análisis.
Supongamos que desea ejecutar un informe sobre las ventas de automóviles por provincia. Si su conjunto de cubos actualmente disponible no incluye información de la provincia, tendrá que pedirle a un ingeniero de datos que cree un nuevo cubo OLAP para usted, o solicitar que modifique un cubo existente para incluir dichos datos de provincia.
El uso del cubo OLAP también significaba que los equipos de datos tenían que administrar tuberías complicadas para transformar los datos de una base de datos SQL en estos cubos. Si estaba trabajando con una gran cantidad de datos, tales tareas de transformación podrían tardar mucho tiempo en completarse, por lo que una práctica común sería ejecutar todas las tuberías ETL (extracción-transformación-carga) antes de que los analistas entraran a trabajar. De esta manera, los analistas no tendrían que esperar a que sus cubos se carguen con los datos más recientes: podrían hacer que las computadoras realicen los trabajos pesados por la noche y comiencen a trabajar inmediatamente por las mañanas. Este enfoque, por supuesto, se volvió más problemático a medida que las empresas se globalizaron y abrieron oficinas en múltiples zonas horarias que exigían acceso a los mismos sistemas analíticos. (¿Cómo maneja sus tuberías en la 'noche' cuando su noche es la mañana de otra oficina?)
El uso de cubos OLAP de esta manera también significaba que las bases de datos SQL y los almacenes de datos debían organizarse de forma remota para facilitar la creación de cubos. Si se convirtió en analista de datos en las dos décadas anteriores, por ejemplo, era muy probable que estuviera capacitado en las artes arcanas del modelado dimensional de Kimball , el modelado de relación de entidad al estilo Inmon o el modelado de bóveda de datos . Estos nombres sofisticados son simplemente métodos para organizar los datos en su almacén de datos para que coincidan con los requisitos analíticos de su empresa.
Kimball, Inmon y sus colegas observaron que se producían ciertos patrones de acceso en todas las empresas. También observaron que un enfoque slap-dash para la organización de datos era una idea terrible, dada la cantidad de tiempo que los equipos de datos dedicaron a crear nuevos cubos para informar. Eventualmente, estos primeros profesionales desarrollaron métodos repetibles para convertir los requisitos de informes comerciales en diseños de almacenamiento de datos, diseños que facilitarían a los equipos extraer los datos que necesitan en los formatos que necesitan para sus cubos OLAP.
Estas restricciones han moldeado la forma y la función de los equipos de datos durante la mayor parte de cuatro décadas. Es importante comprender que las limitaciones tecnológicas muy reales conducen a la creación del cubo OLAP, y las demandas del cubo OLAP llevaron a la aparición de prácticas de equipo de datos que damos por sentado hoy. Por ejemplo:
- Mantener tuberías ETL complejas para modelar nuestros datos.
- Contratar a un gran equipo de ingenieros de datos para mantener estas complicadas tuberías.
- Modelar datos de acuerdo con los marcos de Kimball o Inmon o Data Vault para facilitar la extracción y carga de datos en cubos. (E incluso cuando nos hemos alejado de los cubos, todavía mantenemos estas prácticas para cargar datos en herramientas analíticas y de visualización, independientemente de si están construidas sobre cubos).
- Hacer que el gran equipo de ingenieros de datos también mantenga este segundo conjunto de tuberías (desde el almacén de datos modelado hasta el cubo).
Hoy, sin embargo, muchas de las limitaciones que conducen a la creación del cubo de datos se han aflojado un poco. Las computadoras son más rápidas. La memoria es barata. La nube funciona. Y los profesionales de los datos están comenzando a ver que los cubos OLAP tienen sus propios problemas.
Se marchita el cubo OLAP
Supongamos por un momento que vivimos en un mundo donde la memoria es barata y la potencia informática está fácilmente disponible. Supongamos también que, en este mundo, las bases de datos SQL son lo suficientemente potentes como para venir en sabores OLTP y OLAP. ¿Cómo sería este mundo?
¿Por qué molestarse en seguir un paso adicional de construir y generar nuevos cubos cuando simplemente puede escribir consultas en una base de datos SQL existente?
Para empezar, probablemente dejaríamos de usar cubos OLAP. Esto es estúpidamente obvio: ¿por qué molestarse en dar un paso adicional de construir y generar nuevos cubos cuando simplemente puede escribir consultas en una base de datos SQL existente? ¿Por qué molestarse en mantener un tapiz complejo de tuberías si los datos que necesita para informar se pueden copiar ciegamente de su base de datos OLTP a su base de datos OLAP? ¿Y por qué molestarse en entrenar a sus analistas en algo que no sea SQL?
Esto suena como algo pequeño, pero no lo es: hemos escuchado múltiples historias de horror de analistas que han tenido que depender de ingenieros de datos para construir cubos y establecer tuberías para cada nuevo requisito de informes. Si fuera un analista en esta situación, se sentiría impotente para cumplir con sus plazos. Los usuarios de tu empresa te bloquearían; bloquearías a tus ingenieros de datos; y su ingeniero de datos probablemente estaría lidiando con la complejidad de su infraestructura de datos. Esto es malo para todos. Es mejor evitar la complejidad por completo.
En segundo lugar, si viviéramos en un mundo alternativo donde el cómputo era barato y la memoria era abundante ... bueno, abandonaríamos los esfuerzos serios de modelado de datos.
Esto suena ridículo hasta que lo pienses desde la perspectiva de los primeros principios. Modelamos datos de acuerdo con marcos rigurosos como Kimball o Inmon porque debemos construir regularmente cubos OLAP para nuestros análisis. Históricamente, esto significó un período de diseño de esquema serio. También significó una cantidad constante de trabajo ocupado para mantener ese diseño en nuestros almacenes a medida que cambian los requisitos comerciales y las fuentes de datos.
Pero si ya no usa los cubos OLAP para su análisis, ya no tendrá que extraer datos tan regularmente de su almacén de datos. Y si ya no tiene que extraer datos regularmente de su almacén de datos, entonces no hay razón para tratar su esquema de almacenamiento de datos como algo valioso. Después de todo, ¿por qué hacer todo ese trabajo ocupado si podría simplemente 'modelar' datos creando nuevas tablas 'modeladas' o vistas materializadas dentro de su almacén de datos ... cuando y cuando lo necesite ? Este enfoque tiene todos los beneficios funcionales del modelado de datos tradicional sin la ceremonia o la complejidad que conlleva diseñar y mantener un esquema de estilo Kimball.
Analicemos un ejemplo concreto: digamos que cree que se equivocó de esquema. ¿Qué haces? En nuestro universo alternativo, este problema es simple de resolver: simplemente puede volcar la tabla (o lanzar la vista) y crear nuevas. Y dado que sus herramientas de informes se conectan directamente a su base de datos analítica, esto conduce a una pequeña interrupción: no tiene que volver a escribir un conjunto complejo de tuberías o cambiar la forma en que se crean sus cubos, porque no tiene ningún cubo para crear en primer lugar.
Un nuevo paradigma emerge
La buena noticia es que este universo alternativo no es un universo alternativo. Es el mundo en el que vivimos hoy.
¿Cómo llegamos aquí? Por lo que puedo decir, ha habido tres avances en las últimas dos décadas, dos de los cuales son fáciles de entender. Trataremos con esos dos primero, antes de explorar el tercero con cierto detalle.
El primer avance es una simple consecuencia de la ley de Moore: el cómputo y la memoria se han convertido en bienes reales , y ahora son ridículamente baratos y fácilmente disponibles a través de la nube. Hoy, cualquier persona con una tarjeta de crédito que funcione puede ir a AWS o Google Cloud y tener un servidor arbitrariamente poderoso creado en cuestión de minutos. Este hecho también se aplica a los almacenes de datos basados en la nube: las empresas pueden almacenar y analizar grandes conjuntos de datos con costos fijos prácticamente nulos.
El segundo avance es que la mayoría de los almacenes de datos modernos basados en la nube tienen lo que se conoce como una arquitectura de procesamiento paralelo masivo (MPP). El conocimiento central detrás del desarrollo de las bases de datos MPP es realmente fácil de entender: en lugar de estar limitado por el poder computacional y la memoria de una sola computadora, puede aumentar radicalmente el rendimiento de su consulta si la distribuye entre cientos, si no miles de máquinas. Estas máquinas procesarán su porción de la consulta y pasarán los resultados por la línea para su agregación en un resultado final. El resultado de todo este trabajo es que obtienes mejoras de rendimiento ridículas: BigQuery de Google, por ejemplo, es capaz de realizar una coincidencia completa de expresiones regulares en 314 millones de filas sin índices, y devolver un resultado en 10 segundos (fuente ).
Es fácil decir "ahh, las bases de datos MPP son una cosa", pero ha habido al menos cuatro décadas de trabajo para convertirlo en la realidad que es hoy. En 1985, por ejemplo, la leyenda de la base de datos Michael Stonebraker publicó un artículo titulado The Case for Shared Nothing , un argumento de que la mejor arquitectura para un almacén de datos MPP es aquella en la que los procesadores no comparten nada entre sí. Varios investigadores rechazaron esta opinión, con mucho ruido y pocas nueces compartidas.en 1996; mi punto aquí no es decir que Stonebraker tenía razón y sus críticos estaban equivocados; es para señalar que al principio, incluso preguntas simples como "¿debería un almacén de datos distribuido hacer que sus computadoras compartan memoria o almacenamiento o no?" Era una pregunta abierta que necesitaba investigación. (Si tiene curiosidad: la respuesta a esa pregunta es 'en su mayoría no').
El tercer avance fue el desarrollo y la difusión de almacenes de datos en columnas. Este avance conceptual es realmente el más importante de los tres, y explica por qué las cargas de trabajo OLAP pueden pasar de los cubos a las bases de datos. Deberíamos entender por qué es esto, si queremos entender el futuro de la inteligencia empresarial.
Una base de datos relacional típica almacena sus datos en forma de fila. Una sola fila para una transacción, por ejemplo, contendría los campos date, customer, price, product_sku y así sucesivamente. Sin embargo, una base de datos columnar almacena cada uno de estos campos en columnas separadas. Como muestra la siguiente ilustración (tomada de esta presentación de 2009 de Harizopoulos, Abadi y Boncz ):
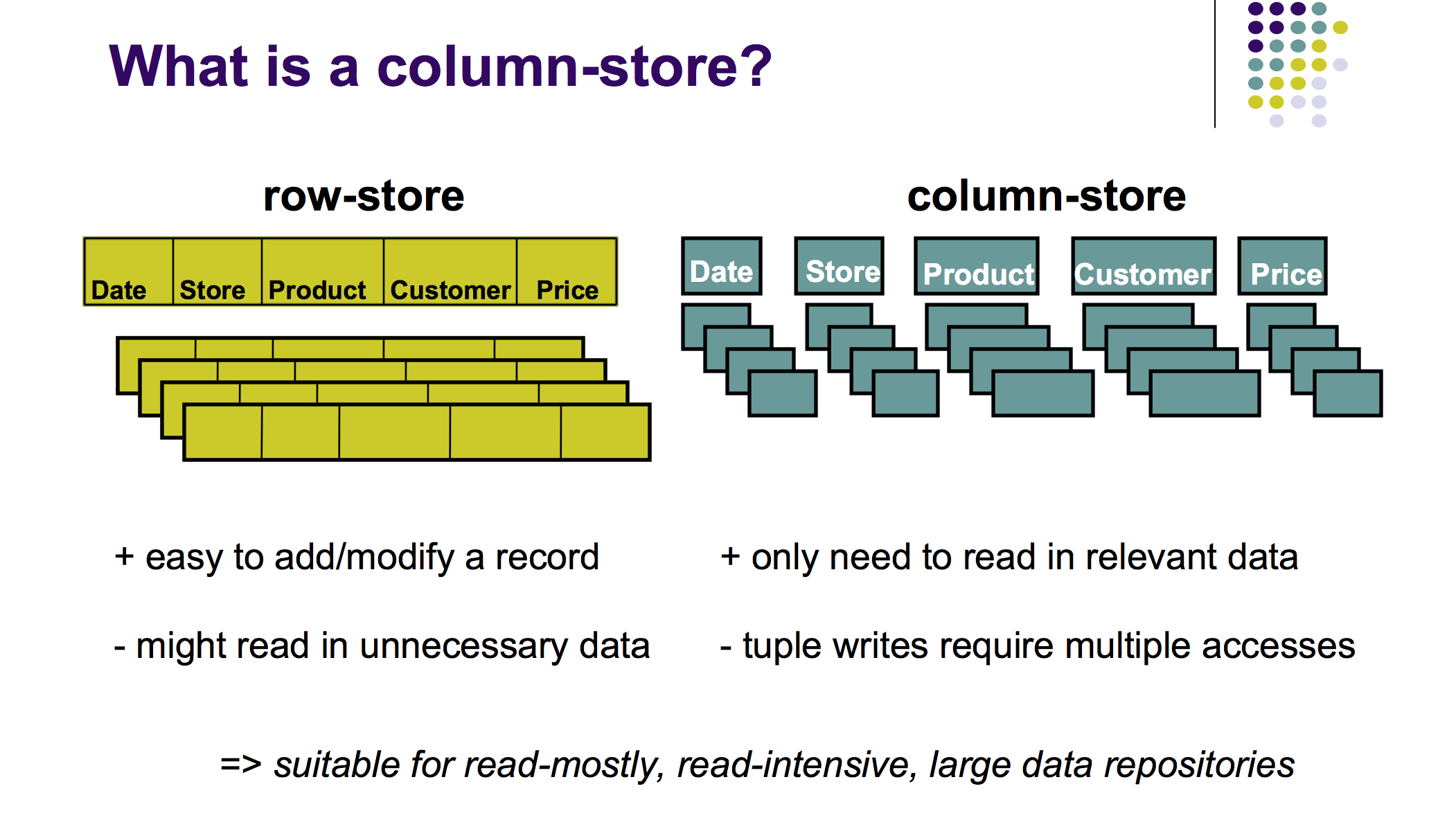
Diferencia entre un RDBMS basado en filas y una base de datos columnar
Si bien los cubos OLAP exigen que cargue un subconjunto de las dimensiones que le interesan en el cubo, las bases de datos en columnas le permiten realizar cargas de trabajo similares de tipo OLAP a niveles de rendimiento igualmente buenos sin el requisito de extraer y construir nuevos cubos. En otras palabras, esta es una base de datos SQL que es perfecta para cargas de trabajo OLAP.
¿Cómo logran las bases de datos en columnas tales proezas de rendimiento? Resulta que hay tres beneficios principales de almacenar sus datos en columnas:
- Las bases de datos en columnas tienen una mayor eficiencia de lectura. Si está ejecutando una consulta como "dame el precio promedio de todas las transacciones en los últimos 5 años", una base de datos relacional tendría que cargar todas las filas de los 5 años anteriores a pesar de que simplemente desea agregar el campo de precio; una base de datos columnar solo tendría que examinar una columna: la columna de precios. Esto significa que una base de datos columnar solo tiene que filtrar una fracción del tamaño total del conjunto de datos.
- Las bases de datos en columnas también se comprimen mejor que las bases de datos relacionales basadas en filas. Resulta que cuando está almacenando piezas de datos similares juntas, puede comprimirlas mucho mejor que si está almacenando piezas de información muy diferentes. (En teoría de la información, esto es lo que se conoce como 'baja entropía'). Como recordatorio, las bases de datos en columnas almacenan columnas de datos, es decir, valores con tipos idénticos y valores similares. Esto es mucho más fácil de comprimir en comparación con los datos de fila, incluso si tiene el costo de algún cálculo (para la descompresión durante ciertas operaciones) cuando está leyendo valores. Pero, en general, esta compresión significa que se pueden cargar más datos en la memoria cuando ejecuta una consulta de agregación, lo que a su vez resulta en consultas generales más rápidas.
- El beneficio final es que la compresión y el empaquetado denso en las bases de datos en columnas liberan espacio, espacio que puede usarse para ordenar e indexar datos dentro de las columnas. En otras palabras, las bases de datos en columnas tienen una mayor eficiencia de ordenación e indexación , lo que es más un beneficio adicional de tener algo de espacio sobrante de una fuerte compresión. También es, de hecho, mutuamente beneficioso: los investigadores que estudian las bases de datos en columnas señalan que los datos ordenados se comprimen mejor que los no clasificados, porque la clasificación reduce la entropía.
El resultado neto de todas estas propiedades es que las bases de datos en columnas le brindan un rendimiento de cubo OLAP sin la molestia de diseñar explícitamente (¡y construir!) Cubos. Significa que puede realizar todo lo que necesita dentro de su almacén de datos y omitir el trabajo laborioso que conlleva el mantenimiento de cubos.
Sin embargo, si hay un inconveniente, es que el rendimiento de la actualización en una base de datos columnar es abismal (tendrá que ir a cada columna para actualizar una 'fila'); Como resultado, muchas bases de datos columnares modernas limitan su capacidad de actualizar los datos después de haberlos almacenado. BigQuery, por ejemplo, no le permite actualizar datos en absoluto: solo puede escribir nuevos datos en el almacén, nunca editar bits viejos . (Actualización: el documento original de Dremel explicaba que BigQuery tenía una estructura de solo agregar; esto ya no es así a partir de 2016).
Conclusión
¿Cuál es el resultado de todos estos desarrollos? Las dos predicciones que hice antes cuando escribía sobre el universo alternativo se están haciendo realidad lentamente: las empresas más pequeñas tienen menos probabilidades de considerar herramientas orientadas al cubo de datos o cargas de trabajo, y el modelado dimensional estricto se ha vuelto menos importante con el tiempo. Más importante aún, las compañías conocedoras de la tecnología como Amazon, Airbnb, Uber y Google han rechazado por completo el paradigma del cubo de datos; Estos eventos y más me dicen que vamos a ver ambas tendencias extendidas en la empresa durante la próxima década.
Sin embargo, solo estamos al comienzo de este cambio. El futuro puede estar aquí, pero está distribuido de manera desigual. Esto es de esperar: las bases de datos en columnas MPP solo han existido durante una década más o menos (BigQuery se lanzó en 2010, Redshift en 2012) y solo hemos visto herramientas que aprovechan este nuevo paradigma (como Looker , dbt y Holistics ) surgieron a mediados de la década anterior. Las cosas todavía son muy tempranas, y tenemos un largo camino por recorrer antes de que las grandes empresas descarten sus sistemas heredados influenciados por cubos y pasen a los nuevos.
Estas tendencias pueden ser interesantes para usted si es un proveedor de servicios de BI, pero centrémonos un poco en las implicaciones de estas tendencias en su carrera. ¿Qué significa para usted si es un profesional de datos y los cubos OLAP están en decadencia?
Tal como lo veo, tendrás que patinar hacia donde está el disco:
Master SQL; La mayoría de las bases de datos en columnas MPP se han asentado en SQL como el estándar de consulta de facto. (Más sobre esto aquí ).
Sospeche de las compañías que están fuertemente bloqueadas en el flujo de trabajo del cubo OLAP. (Aprenda cómo hacer esto aquí ).
Familiarícese con las técnicas de modelado para la edad de la base de datos columnar (Chartio es probablemente la primera compañía que he visto con una guía que intenta esto; lea eso aquí ... pero entienda que esto es relativamente nuevo y las mejores prácticas aún pueden estar cambiando).
Use ELT siempre que sea posible (en lugar de ETL); Este es el resultado del nuevo paradigma .
Estudie las metodologías de Kimball, Inmon y la bóveda de datos, pero con miras a la aplicación en el nuevo paradigma. Comprender las limitaciones de cada uno de sus enfoques.
Comencé esta pieza con un enfoque en el cubo OLAP como una forma de comprender una tecnología central en la historia de la inteligencia empresarial. Pero resulta que la invención del cubo ha influido en casi todo lo que hemos visto en nuestra industria. Presta atención a su declive: si no le quitas nada más a esta pieza, déjalo ser esto: el ascenso y la caída del cubo OLAP es más importante para tu carrera de lo que podrías pensar originalmente.
Originalmente publicado en: https://www.holistics.io/blog/the-rise-and-fall-of-the-olap-cube/